Architecting the Future of Recurly
Over the past few weeks, we’ve had dozens of conversations with our customers regarding our hardware outage. We want to make to every attempt to be honest and transparent about the various problems that coalesced into an incident on Labor Day that resulted in our inability to decrypt some stored credit card data.
This post will share what we know, what we’ve learned and how our thinking has changed. We’ve been fortunate to have the help of outside experts in these efforts, including Marty Abbott, the ex-CTO of eBay (and currently a principal with AKF Partners). Marty has been on-site with us to provide guidance and insight into our design plans going forward.
The Incident and Immediate Response
Our infrastructure has been designed to provide fail-over and redundancy in all areas of the system. During this incident, a failure occurred in our master hardware encryption appliance. These devices are designed to encrypt sensitive data using a primary encryption key stored in a hardware encryption chip (TPM chip) coupled with daily software-based key rotation. When the encryption chip in the primary appliance failed, the slave device continued backing up encrypted data from the primary appliance as designed. However, when we promoted the slave appliance to take over from the master, we discovered that it was unable to decrypt the data it had received from the primary appliance. Unfortunately in this instance, our own security measures worked against us in a manner we didn’t foresee.
Lesson #1
When engineers design systems, they initially design for how systems should behave when a single piece of the system fails — and they test a large number of scenarios. This is something we did at Recurly. Only the most sophisticated architectural designs plan for both primary and backup systems to fail (e.g., NASA onboard navigational computers).
On the day of the outage we had two additional encryption appliances on hand in preparation for installation at our New York data center. These two appliances were put into service within hours, and we removed the faulty appliance from service for bench diagnostics. We now have master-slave-slave replication in place with additional data “snapshots” being taken daily. These snapshots are encrypted and archived in separate offline devices.
Architectural Clarity
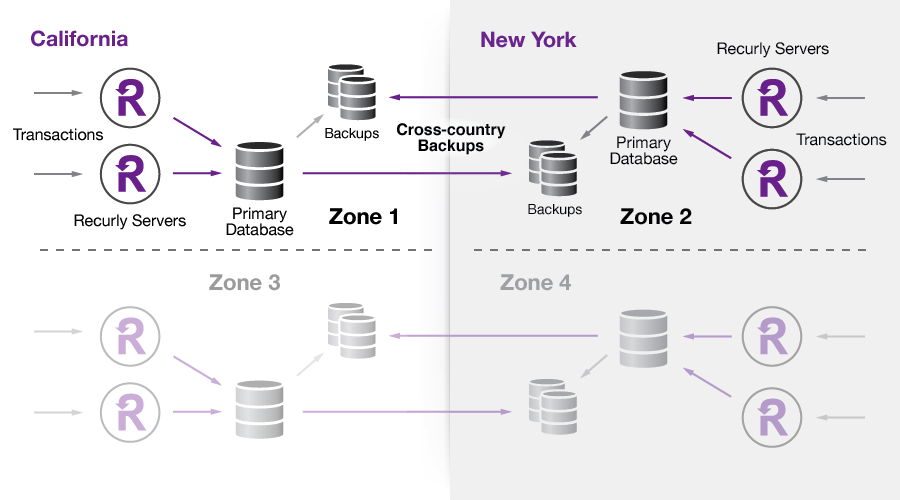
With Marty Abbott on-site at Recurly offices, we designed a detailed and comprehensive architectural plan designed to deliver a) High Availability Service, b) Data Resiliency and c) Fault Isolation. By definition, our architecture has to be distributed across multiple geographies, but the key requirement for us was to do so without introducing an unsustainable amount of complexity into the system.
Each data center will employ multiple instances of Recurly service architecture called “swimlanes.” This architectural approach is not unique to Recurly. It has been employed by many other mission critical services whose businesses demand very little margin for error across high availability, data integrity, and security. In fact, this is very similar to the architectural approach employed by Salesforce.com, as you can see from their status site: http://status.salesforce.com/trust/status
Lesson #2
Multiple data centers make sense for a variety of reasons. Having infrastructure in the same geography as employees is not a good idea. We live in California. We have earthquakes. We don’t want employees to have to make a choice between infrastructure restoration and personal/family safety.
Revised Plans For Our Second Data Center
Our revised plans for our backup data center place service operations for each merchant inside a dedicated set of isolated infrastructure. Each “swimlane” will have full redundancy and data replication, along with remote data replication in an alternate data center for additional backups in the event that disaster recovery is required.
This notion of infrastructure “swimlanes” allows for fault-isolation and data resiliency without having to introduce the complexity and risk of multi-master replication. It also allows for a much faster recovery time in the event that an outage does occur.
Lesson #3
Start the design exploration by identifying the end objective (and desired results), and work backwards to the most appropriate solution for the size of the organization that is available to maintain it. This approach helped us achieve the desired objective without adding significant amount of risk through complex system design.
We’re Building Now
We had already committed to our second data center in New York prior to the outage. After consulting with Marty Abbott, we’ve ordered not just 2x the amount of hardware and equipment, but 4x the amount so we can put multiple “swimlanes” in each data center for added fault-isolation and greater data resiliency.
An overview of our current data center plan:
A Brighter, Stronger Recurly
Our plans have been greatly informed by bringing in industry veterans to consult with us so that we can build a great company. We will continue to post regular updates as we build out our second data center and execute through additional architectural milestones.
Our team is excited about our plans and we look forward to delivering the enhanced level of service resiliency that our customers rightfully expect and deserve.
More great things to come,

Isaac Hall, CTO





